






Google today announced that it is working with a number of news organizations to surface more data from their data journalism projects in its search results. The idea here is to make it easier to discover the data that a lot of these organizations produce and then surface it in an easy to read format on the company’s search results pages.
The company is currently working with a few news organizations, including ProPublica, to produce the structured data in the format it needs for its search index. As long as that data is in a table, adding it to the index should be pretty straightforward.
“As a news organization that is focused on having real-world impact, it’s very much in our mission to give people information at the point of need,” said Scott Klein, the deputy managing editor of ProPublica. “If we can make the data we’ve worked hard to collect and prepare available to people at the very moment when they’re researching a big life decision, and thereby help them make the best decision they can, it’s an absolute no-brainer for us. And the code is trivial to add.”
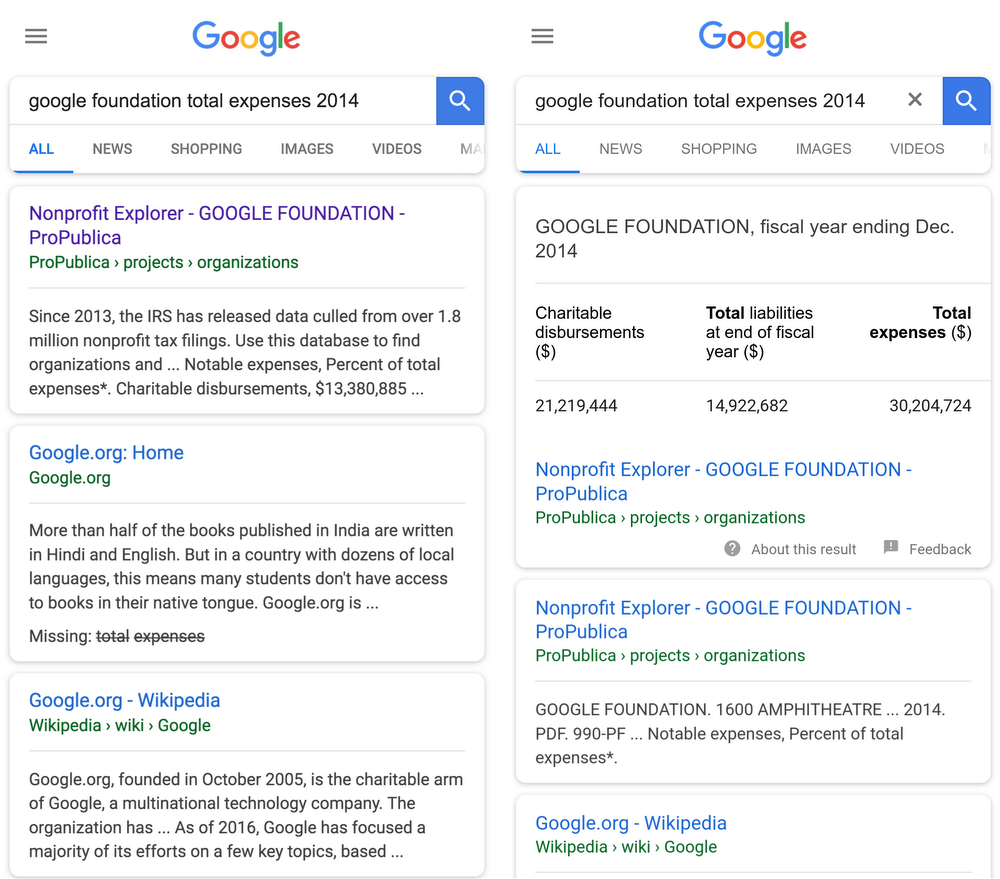
Any news organizations that produce this kind of data can follow Google’s guidelines and have their data indexed. For the right queries, the result of that is going to be prime placement on Google’s search results pages, so it’s probably worth the effort. That first results, after all, is all that counts.
It’s worth noting that Google already indexes and highlights lots of other data it finds online, but this is the first time it’s making a concerted effort to include journalism projects, too.






from TechCrunch https://ift.tt/2vmPNmZ

0 comments:
Post a Comment