
By DEB AMLEN Crosswords & Games https://nyti.ms/2BevV9z








Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Jordan Novet / CNBC:
AWS's Q4 revenue of $7.43B AWS beat analyst estimates of $7.29B; AWS accounted for 58% of Amazon's overall operating income in Q4 — Amazon's cloud-computing division said revenue jumped 45 percent in the fourth quarter, as the company continued to cement its lead over Microsoft and Google.
Keeping its spot among the top countries who are competing in the space race, China is planning to launch 30 missions this year, according to information from the state-run China Aerospace Science and Technology Corp., reported by the Xinhua news agency.
Last year, China outpaced the United States in the number of national launches it had completed through the middle of December, according to a report in the MIT Technology Review. Public and private Chinese companies launched 35 missions that were reported to the public through 2018 compared to 30 from the U.S., wrote Joan Johnson-Freese, a professor of national security affairs at the Naval War College.
“Privately funded space startups are changing China’s space industry,” Johnson-Freese wrote at the time. “And even without their help, China is poised to become a space power on par with the United States.”
Major missions for 2019 will include the Long March-5 large carrier rocket, whose last launch was marred by malfunction. If the new Long March launch goes well, China will stage another flight to launch a probe designed to bring lunar samples back to Earth at the end of 2019.
China will also send still another version of the Long March rocket to the lay the groundwork for the country’s private space station.
While the bulk of China’s activity in space is being handled through government ministries and state owned companies, private companies are starting to make their mark as well.
Landspace, OneSpace and iSpace form a triumvirate of privately held Chinese companies that are all developing launch vehicles and planning to carry payloads to space.
In all, using some back of the napkin math and the calendar of launches available at Spaceflight Insider , there were roughly 80 major rocket launches this year that were scheduled.
Those figures mean that over once a week a rocket blasted off to deliver some sort of payload to a place above the atmosphere. RocketLab put its first commercial payload into orbit in November, and launched a second rocket the following month. Meanwhile, SpaceX, the darling of the private space industry, launched 21 rockets itself.






Notification spam ruins social networks, diluting the real human interaction. Desperate to gain an audience, users pay services to rapidly follow and unfollow tons of people in hopes that some will follow them back. The services can either automate this process or provide tools for users to generate this spam themselves, Earlier this month, a TechCrunch investigation found over two dozen follow-spam companies were paying Instagram to run ads for them. Instagram banned all the services in response an vowed to hunt down similar ones more aggressively.
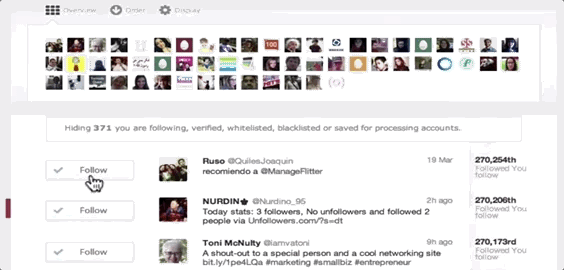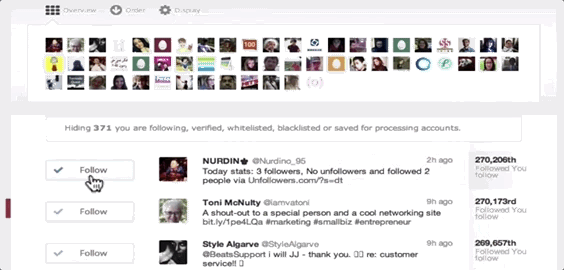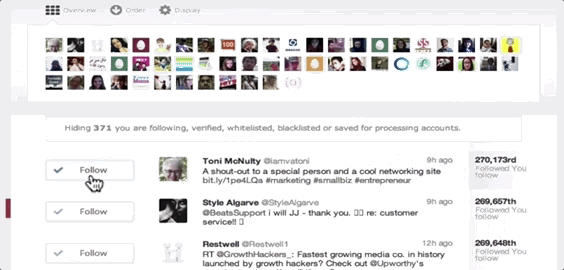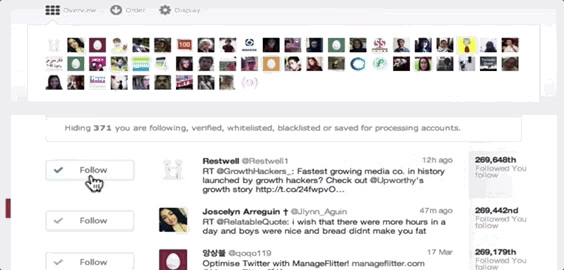
ManageFlitter’s spammy follow/unfollow tools
Today, Twitter is stepping up its fight against notification spammers. Earlier today, the functionality of three of these services — ManageFlitter, Statusbrew, Crowdfire — ceased to function, as spotted by social media consultant Matt Navarra.
TechCrunch inquired with Twitter about whether it had enforced its policy against those companies. A spokesperson provided this comment: “We have suspended these three apps for having repeatedly violated our API rules related to aggressive following & follow churn. As a part of our commitment to building a healthy service, we remain focused on rapidly curbing spam and abuse originating from use of Twitter’s APIs.” These apps will cease to function since they’ll no longer be able to programatically interact with Twitter to follow or unfollow people or take other actions.
Twitter’s policies specify that “Aggressive following (Accounts who follow or unfollow Twitter accounts in a bulk, aggressive, or indiscriminate manner) is a violation of the Twitter Rules.” This is to prevent a ‘tragedy of the commons’ situation. These services and their customers exploit Twitter’s platform, worsening the experience of everyone else to grow these customers’ follower counts. We dug into these three apps and found they each promoted features designed to help their customers spam Twitter users.
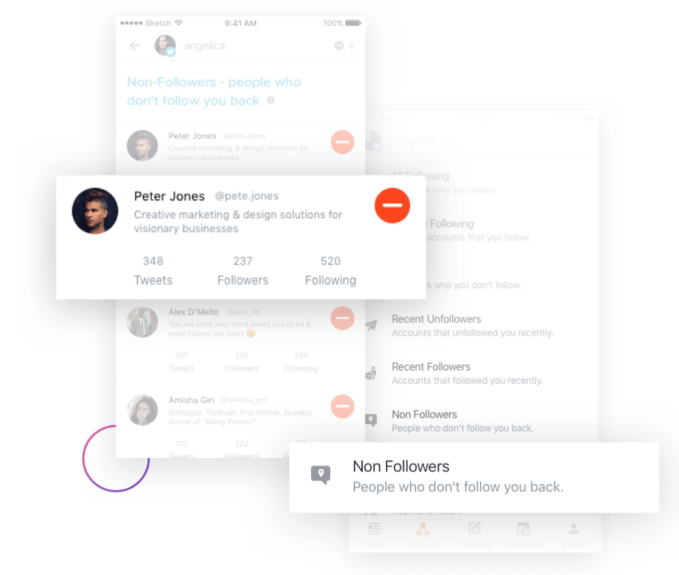
ManageFlitter‘s site promotes how “Following relevant people on Twitter is a great way to gain new followers. Find people who are interested in similar topics, follow them and often they will follow you back.” For $12 to $49 per month, customers can use this feature shown in the GIF above to rapidly follow others, while another feature lets them check back a few days later and rapidly unfollow everyone who didn’t follow them back.
Crowdfire had already gotten in trouble with Twitter for offering a prohibited auto-DM feature and tools specifically for generating follow notifications. Yep it only changed its functionality to dip just beneath the rate limits Twitter imposes. It seems it preferred charging users up to $75 per month to abuse the Twitter ecosystem than accept that what it was doing was wrong.
StatusBrew details how “Many a time when you follow users, they do not follow back . . . thereby, you might want to disconnect with such users after let’s say 7 days. Under ‘Cleanup Suggestion’ we give you a reverse sorted list of the people who’re Not Following Back”. It charges $25 to $416 month for these spam tools. After losing its API access today, StatusBrew posted a confusing half-mea culpa, half-“it was our customers’ fault” blog post announcing it will shut down its follow/unfollow features.
Twitter tells TechCrunch it will allow these companies “apply for a new developer account and register a new, compliant app” but the existing apps will remain suspended. I think they deserve an additional time-out period. But still, this is a good step towards Twitter protecting the health of conversation on its platform from greedy spam services. I’d urge the company to also work to prevent companies and sketchy individuals from selling fake followers or follow/unfollow spam via Twitter ads or tweets.
When you can’t trust that someone who follows you is real, the notifications become meaningless distractions, faith in finding real connection sinks, and we become skeptical of the whole app. It’s the users that lose, so it’s the platforms’ responsibility to play referee.


Houzz, a $4 billion-valued home improvement startup that recently laid off 10 percent of its staff, has admitted a data breach.
A reader contacted TechCrunch on Thursday with a copy of an email sent by the company. It doesn’t say much — such as when the breach happened, or if a hacker to blame or if it was a data exposure that the company could’ve prevented.
Houzz spokesperson Gabriela Hebert would not comment beyond an FAQ posted on the company’s website, citing an ongoing investigation.
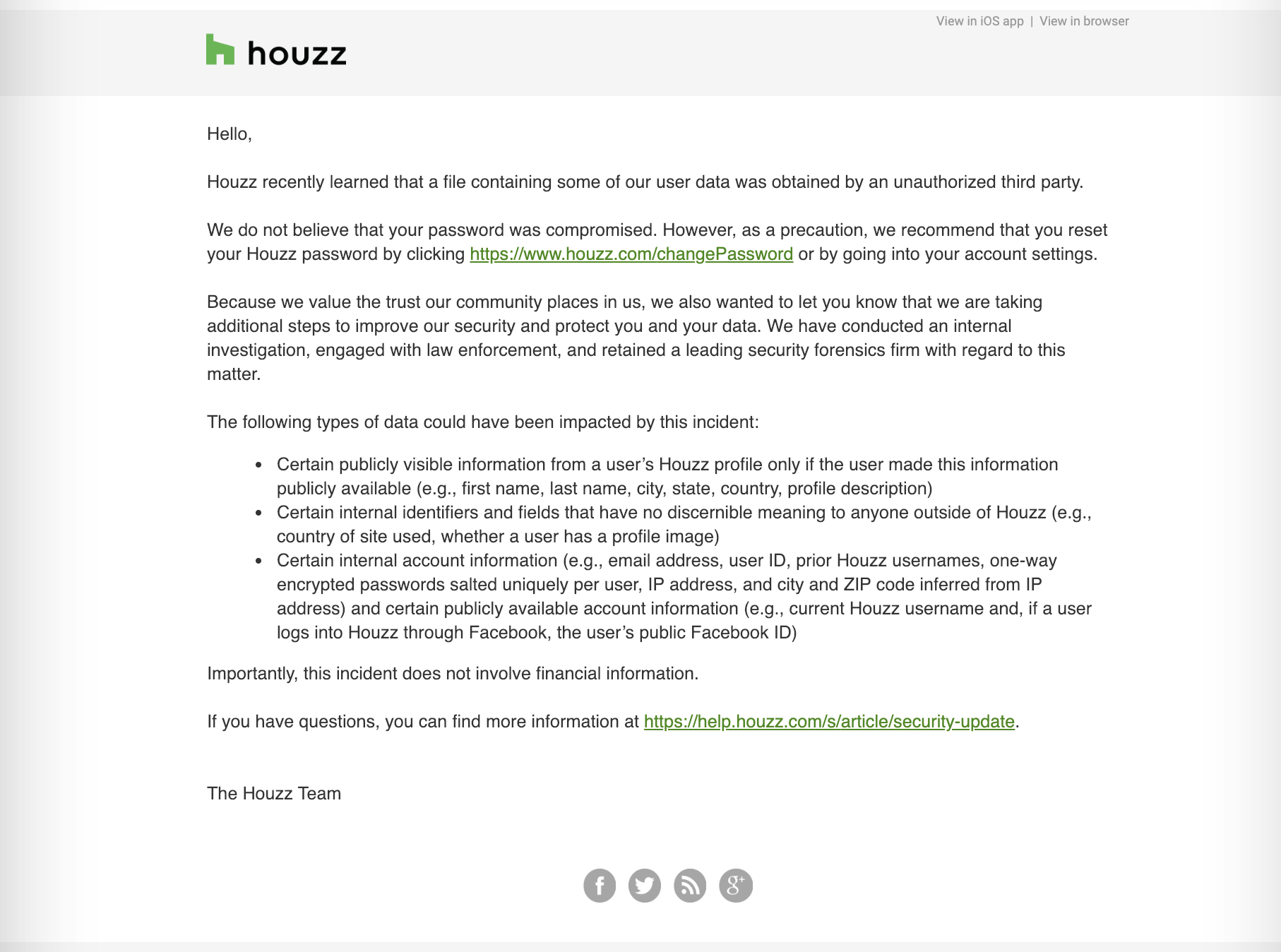
In that FAQ, the company said it “recently learned that a file containing some of our user data was obtained by an unauthorized third party.” It added: “We immediately launched an investigation and engaged with a leading forensics firm to assist in our investigation, containment, and remediation efforts.”
The company said it was notifying all of its users who may have been affected.
An email from a Houzz user. (Image: supplied)
Houzz said some publicly visible information from a user’s Houzz profile, such as name, city, state, country and profile description, along with internal identifiers and fields “that have no discernible meaning to anyone outside of Houzz,” such as the region and location of the user and if they have a profile image, for example, the company said.
The company also said that usernames and scrambled passwords were also taken.
Houzz said that the passwords were scrambled and salted using a one-way hashing algorithm, but did not provide specifics on what kind of hashing algorithm was used. Some algorithms, like MD5, are old and outdated but still in use, while newer hashing algorithms — like bcrypt — are stronger and can be more difficult to crack, depending on the number of rounds the passwords go through.
Regardless, the company recommended users change their passwords.
No financial information was taken, according to the FAQ.
The company was last year among many mocked for sending out emails to users alerting them of mandatory changes to their privacy policies ahead of the 2018-introduced EU General Data Protection Regulation (GDPR) law, saying it “value[s]” its customers privacy. “Their opening lines offer a glimpse of the way legal policy and user experience are colliding under the new regulations,” said Fast Company.
But it’s not clear if the company will face penalties — up to four percent of its global revenue — as a result of the regulation, only that the company “notified EU authorities within the statutory period,” said the spokesperson.
Another day, another breach.



Tom Warren / The Verge:
Apple shuts down Google's ability to distribute internal iOS apps, blocking Gbus staff transportation app and beta versions of Maps, Hangouts, Gmail, and others — Google joins Facebook in Apple's banning spree — Apple has now shut down Google's ability to distribute its internal iOS apps …
Amazon.com, Inc.:
Amazon.com Announces Fourth Quarter Sales up 20% to $72.4 Billion — Amazon.com, Inc. (NASDAQ: AMZN) today announced financial results for its fourth quarter ended December 31, 2018. — Operating cash flow increased 67% to $30.7 billion for the trailing twelve months …

Ingrid Lunden / TechCrunch:
The Saudi startup behind anonymous commenting app Sarahah, banned by Apple and Google over bullying, launches Enoff, a workplace anonymous feedback app for iOS — Sarahah, the anonymous messaging app founded in Saudi Arabia that became an unexpected viral sensation with teens …
More than a year after net neutrality was essentially abolished by a divided Federal Communications Commission, a major legal challenge supported by dozens of companies and advocates has its day in court tomorrow. Mozilla v. FCC argues that the agency’s decision was not just dead wrong, but achieved illegally.
“We’re not just going into court to argue that the FCC made a policy mistake,” said Public Knowledge VP Chris Lewis in a statement. “It broke the law, too. The FCC simply failed in its responsibility to engage in reasoned decision-making.”
Oral arguments before the D.C. Circuit Court of Appeals commence Friday, February 1, though the FCC attempted to have the date put off due to the shutdown — and the request was denied.
The legal challenge is one of several tacks being taken against the FCC’s replacement of 2015’s net neutrality rules with a much weaker one last year. As with any rule or law, there are multiple avenues for dissent; a direct legal challenge is among the quickest and most public.
Mozilla, along with Vimeo, Etsy, Public Knowledge, INCOMPAS, and a number of other companies and organizations, filed the challenge shortly after the new rules took effect, but these things take time to creep through the court system.
The lawsuit has a number of primary arguments against the rulemaking (you can read the full brief here), but they boil down to two basic ideas, which I’ve attempted to summarize below:
First and most important, the FCC’s entire argument that broadband is not a telecommunications service is false. This argument goes back decades, and you can read the history of it here. The short version is: telecommunication services move data from point to point, and information services do things with that data. The FCC argues that because broadband connections let you, for example, buy something online, that connection essentially is a store.
Supreme Court Justice Kavanaugh made this same very elementary mistake and was set right by a judge a couple years ago. It’s basically indefensible and no one who understands how the internet works agrees with it. As the Mozilla filing puts it, the argument “confuse[s] the road with the destination.”
The FCC also says that DNS services and caching, some of the nuts and bolts of how the internet and web work, count as information services — which is perfectly true — and that because broadband uses them, it too is an information service instead of telecommunications — which is ridiculous. It’s like saying that if a road has signs on it, the road is itself a sign. Nope. The filing again resorts to metaphor, saying “a few drops of fresh water do not turn an ocean into a lake.”
This is the primary support for the FCC’s entire case, and removing it would essentially nullify the entire new set of rules, since if the judges agree that broadband is in fact telecommunications, the industry is governed by a whole different set of statutes under the Communications Act. There are numerous other sub-arguments here that could also come into play.
Second, the FCC’s decision is “arbitrary and capricious,” and thus illegal under the Administrative Procedures Act, which requires certain standards of evidence and method to be shown in the establishment of such rules. This is supported in a number of ways, including the authority argument above. It also failed to address consumer and other complaints during the rulemaking process.
The FCC also does not justify its argument that the broadband industry is better suited to regulation by antitrust authorities, and does not justify rejection of certain other statutory authorities under which the FCC could be responsible for some of the rules. “The FCC does not adequately explain why other statutes, developed to address other problems, just happen to do the job Congress assigned to the FCC,” argue Mozilla et al.
The agency’s cost-benefit analysis, documentation required for new rules like this, is also inadequate, they argue. Certainly economic analysis of multiple major industries can be debated forever, but there are pretty basic questions unanswered or evaded here, which weakens the FCC’s entire case.
For the record, the FCC’s arguments and counter-arguments are set forth in the rule itself and court filings largely reiterate the same points.
All these arguments are not particularly new — they’ve been brought out and revised multiple times both before and after the net neutrality decision. But this is an important setting in which for them to be addressed. This panel of judges could essentially render the FCC’s rules or rulemaking process inadequate, illegal, or incorrect — or all three — and send the agency back to the drawing board.
These decisions take a great deal of time to arrive, so be ready for a wait just like the one we’ve had for the arguments to make it to court in the first place. But the wheels are in motion and it could be that in a few months’ time net neutrality will have new life.
Of course, if the FCC won’t keep net neutrality around, states will — and that’s a whole other legal battle waiting to happen.
“Comcast, Verizon, and AT&T are going to wish they never picked this fight with the Internet,” said Fight for the Future’s Evan Greer. “Internet activists are continuing to fight in the courts, in Congress, and in the states. Net neutrality is coming back with a vengeance. It’s only a matter of time.”


Like many modern digital innovations, “crowdsourcing” is a concept borrowed from the commercial tech industry. It is a method to solicit ideas from the Internet masses to complete a task or solve a challenge. It seems a perfect fit for Congress, an entire branch of government stuck in the past, losing public legitimacy and increasingly ineffective in policymaking.
Even though it is the world’s most powerful representative assembly, Congress is working at 45% less expert capacity than it had in the 1970s. It has remained in this state of dereliction despite accumulating millions more constituents and demands for consideration. Plus, its most important policy bridge to the public–committee hearings–have declined, sometimes by 50% or more.
It’s obvious that Congress could use collaborative assistance.
Yet in a weaponized information environment, crowdsourcing appears unproductive and even ominous. Take social media platforms. Five years ago, Facebook and Twitter looked like promising venues for more regular voices to provide feedback in the policy making process. But given the lack of civic guardrails like moderation or verified identity, that “crowd” too often behaves like a hired mob.
My colleague Nate Wong is familiar with crowdsourcing from his years of consulting. He notes that before throwing our hands up, there are some key elements of crowdsourcing to unpack. “Some people would say that crowdsourcing works, but it’s not as effective because the crowd is not curated well.”
At this time, crowdsourcing does not work for policy making in Congress because participants are not organized for it and the institution itself lacks a curation method for credible input.
Years ago, author James Surowiecki noted that crowds can be wise if they are diverse, if individuals are independent, and if participants are decentralized with locally specific knowledge. Crucially, there also needs to be a mechanism for aggregating input.

Image: Bryce Durbin/TechCrunch
Congress should be this mechanism. Informed public deliberation should be its forte. But right now, our system does not have the capacity nor the incentives to reap the benefits of collective wisdom. Before we jump to crowdsourcing, we must ask ourselves, how much assistance can be useful outside the institution unless the in-house capacity exists to process it? And, how much can we citizens expect our leaders to take risks on behalf of democratic discourse when flash-mobs, ambush tactics and armies of contempt lurk in every public space? As it stands, Congress does not have the technical infrastructure to ingest all this new input in any systematic way. Individual members lack a method to sort and filter signal from noise or trusted credible knowledge from malicious falsehood and hype.
What Congress needs is curation, not just more information.
Curation means discovering, gathering and presenting content. This word is commonly thought of as the job of librarians and museums, places we go to find authentic and authoritative knowledge. Similarly, Congress needs methods to sort and filter information as required within the workflow of lawmaking. From personal offices to committees, members and their staff need context and informed judgement based on broadly defined expertise. The input can come from individuals or institutions. It can come from the wisdom of colleagues in Congress or across the federal government. Most importantly it needs to be rooted in local constituents and it needs to be trusted.
It is not to say that crowdsourcing is unimportant for our governing system. But input methods that include digital must demonstrate informed and accountable deliberative methods over time. Governing is the curation part of democracy. Governing requires public review, understanding of context, explanation and measurements of value for the nation as a whole. We are already thinking about how to create an ethical blockchain. Why not the same attention for our most important democratic institution?
Governing requires tradeoffs that elicit emotion and sometimes anger. But as in life, emotions require self-regulation. In Congress, this means compromise and negotiation. In fact, one of the reasons Congress is so stuck is that its own deliberative process has declined at every level. Besides the official committee process stalling out, members have few opportunities to be together as colleagues, and public space is increasingly antagonistic and dangerous.

Image: Bryce Durbin/TechCrunch
With so few options, members are left with blunt communications objects like clunky mail management systems and partisan talking points. This means that lawmakers don’t use public input for policy formation as much as to surveil public opinion.
Any path forward to the 21st century must include new methods to (1) curate and hear from the public in a way that informs policy AND (2) incorporate real data into a results-driven process.
While our democracy is facing unprecedented stress, there are bright spots. Congress is again dedicating resources to an in-house technology assessment capacity. Earlier this month, the new 116th Congress created a Select Committee on the Modernization of Congress. It will be chaired by Rep. Derek Kilmer (WA, 6). Then the Open Government Data Act became law. This law will potentially scale the level of access to government data to unprecedented levels. It will require that all public facing federal data must be machine-readable and reusable. This is a move in the right direction, and now comes the hard part.
Marci Harris, the CEO of civic startup Popvox put it well, “The Foundations for Evidence-Based Policymaking (FEBP) Act, which includes the OPEN Government Data Act, lays groundwork for a more effective, accountable government. To realize the potential of these new resources, Congress will need to hire tech literate staff and incorporate real data and evidence into its oversight and legislative functions.”
In forsaking its own capacity for complex problem solving, Congress has become non-competitive in the creative process that moves society forward. During this same time period, all eyes turned toward Silicon Valley to fill the vacuum. With mass connection platforms and unlimited personal freedom, it seemed direct democracy had arrived. But that’s proved a bust. If we go by current trends, entrusting democracy to Silicon Valley will give us perfect laundry and fewer voting rights. Fixing democracy is a whole-of-nation challenge that Congress must lead.
Finally, we “the crowd” want a more effective governing body that incorporates our experience and perspective into the lawmaking process, not just feel-good form letters thanking us for our input. We also want a political discourse grounded in facts. A “modern” Congress will provide both, and now we have the institutional foundation in place to make it happen.


Facebook just announced its latest round of “coordinated inauthentic behavior,” this time out of Iran. The company took down 262 Pages, 356 accounts, three Facebook groups and 162 Instagram accounts that exhibited “malicious-looking indicators” and patterns that identify it as potentially state-sponsored or otherwise deceptive and coordinated activity.
As Facebook Head of Cybersecurity Policy Nathaniel Gleicher noted in a press call, Facebook coordinated closely with Twitter to discover these accounts, and by collaborating early and often the company “[was] able to use that to build up our own investigation.” Today, Twitter published a postmortem on its efforts to combat misinformation during the US midterm election last year.

Example of the content removed
As the Newsroom post details, the activity affected a broad swath of areas around the globe:
“There were multiple sets of activity, each localized for a specific country or region, including Afghanistan, Albania, Algeria, Bahrain, Egypt, France, Germany, India, Indonesia, Iran, Iraq, Israel, Libya, Mexico, Morocco, Pakistan, Qatar, Saudi Arabia, Serbia, South Africa, Spain, Sudan, Syria, Tunisia, US, and Yemen. The Page administrators and account owners typically represented themselves as locals, often using fake accounts, and posted news stories on current events… on topics like Israel-Palestine relations and the conflicts in Syria and Yemen, including the role of the US, Saudi Arabia, and Russia.
Today’s takedown is the result of an internal investigation linking the newly discovered activity to other activity from August. Remarkably, the activity Facebook flagged today dates back to 2010.
The Iranian activity was not focused on creating real world events, as we’ve seen in other cases. In many cases, the content “repurposed” reporting from Iranian state media and spread ideas that could benefit Iran’s positions on various geopolitical issues. Still, Facebook declined to link the newly identified activity to Iran’s government directly.
“Whenever we make an announcement like this we’re really careful,” Gleicher said. “We’re not in a position to directly assert who the actor is in this case, we’re asserting what we can prove.”


